The Portal to the Language of the Anglo-Saxons
Old-Engli.sh
Trivia
Investigation of the decline of the Old English inflected infinitive
This page presents the collection, analysis and graphical representation of data regarding the decline of Old English inflected infinitives. The data and the graph are referenced in the Old-Engli.sh Trivia article 'Inflected Infinitives? Sure enough, in Old English!' The page also provides the exact CopusSearch queries and R code used.
The data
How was the data collected?
The data was collected with CorpusSearch2, a program for extracting sentences from syntactically parsed corpora.
The Old English data comes from the York-Toronto-Helsinki Parsed Corpus of Old English Prose. The following search query was used to find inflected infinitives:
node: IP-INF*
query:
(IP-INF* idoms VB^D|BE^D|HV^D|AX^D|MD^D)
AND (IP-INF* idoms TO)
AND (TO idoms !\**)
This query looks for all infinitival clauses (node: IP-INF*) that contain an infinitive of full lexical verbs (VB), be (BE), have (HV), auxiliaries (AX) and modals (MD) which are inflected for dative case (that's what the final ^D means). Furthermore, the infinitival clause should occur with the non-finite marker to, but only if it is not empty (that requirement is set by the last line, (TO idoms !\**). This query finds examples like, to leornianne mid his geferum. (cobede,Bede_3:3.162.4.1555) 'to learn with his companions', with the inflected infinitive, leornianne.
The search query for uninflected infinitives is very similar:
node: IP-INF*
query:
(IP-INF* idoms VB|BE|HV|AX|MD)
AND (IP-INF* idoms TO)
AND (TO idoms !\**)
The only difference is that the infinitives should not be marked for a dative case ending (there is no ^D on the verbs). This query will find examples such as, to leornigen +turh +tone rihtne geleafe, (coalcuin,Alc_[Warn_35]:14.14) 'to learn through the right belief', with an uninflected infinitive, leornigenØ.
For the Middle English data, search queries were written for the Penn-Parsed Corpus of Middle English that are as similiar to the Old English searches as possible. The main difference is that the Middle English corpus does not include case markings. Therefore, literal strings were defined to find inflected and uninflected infinitives. Here is the search query to find inflected infinitives in Middle English:
node: IP-INF*
query:
(IP-INF* idoms VB|BE|HV|DO|MD)
AND (VB|BE|HV|DO|MD idoms *a*ene|*a*ane|*a*yne|*a*ine|
*a*enne|*a*anne|*a*ynne|*a*inne|
*e*ene|*e*ane|*e*yne|*e*ine|
*e*enne|*e*anne|*e*ynne|*e*inne|
*i*ene|*i*ane|*i*yne|*i*ine|
*i*enne|*i*anne|*i*ynne|*i*inne|
*o*ene|*o*ane|*o*yne|*o*ine|
*o*enne|*o*anne|*o*ynne|*o*inne|
*u*ene|*u*ane|*u*yne|*u*ine|
*u*enne|*u*anne|*u*ynne|*u*inne|
*y*ene|*y*ane|*y*yne|*y*ine|
*y*enne|*y*anne|*y*ynne|*y*inne)
AND (IP-INF* idoms TO)
AND (TO idoms !\**)
As before, all infinitival clauses are considered (node: IP-INF*) that dominate an infinitive of a lexical verb (VB), be (BE), have (HV), do (DO) and modals (MD). These infinitives must consist at least of a vowel in the stem of the verb (a, e, i, o, u, y) and a potential inflectional ending (like ene, anne, inne etc.). That is the long list of strings joined together with pipes in the first AND condition. Again, the infinitival clause must contain a non-empty non-finite marker to. This query finds, for example, the following infinitival clause, +ta ateorigendlice +ting by+d swa
behefe & leofe to brucane (CMKENTHO,142.210) 'the transitory things are so appropriate and dear to enjoy', with an inflected infinitive, brucane.
Finally, uninflected infinitives in Middle English were found with this search query:
node: IP-INF*
query:
(IP-INF* idoms VB|BE|HV|DO|MD)
AND (VB|BE|HV|DO|MD idoms *a*en|*a*an|*a*yn|*a*in|
*e*en|*e*an|*e*yn|*e*in|
*i*en|*i*an|*i*yn|*i*in|
*o*en|*o*an|*o*yn|*o*in|
*u*en|*u*an|*u*yn|*u*in|
*y*en|*y*an|*y*yn|*y*in)
AND (IP-INF* idoms TO)
AND (TO idoms !\**)
It is essentially identical to the previous search except that the verb must now end in a typical, uninflected early Middle English infinitival ending, like an, en, in etc. This query finds examples like the following, frigdom to geceosan god o+d+de yefel (CMKENTHO,141.185) 'freedom to choose good or evil', with an uninflected infinitive, geceosanØ.
What does the data look like?
The search queries were run on 63 Old and early Middle English texts. The resultant example counts were put into a spreadsheet, formatted in such a way that for every text, one column recorded the text name, another column the approximate year of composition, a third column the number of examples of inflected infinitives and a final column the number of examples of uninflected infinitives. The dates of composition are certainly controversial. It would lead much too far to attempt a justification of the assumed exemplar dates here. It must suffice to say that some fitted years may indeed have to be revised but that, generally, the assumed points of origins are probably accurate enough for morpho-syntactic studies like the one done here, based on various pieces of evidence, including other syntactic investigations.
The table below presents the complete, final data set.
## |Text_Name | Fitted| Inflected | Uninflected |
## | | _Year | _Examples | _Examples |
## |:----------------------|------:|----------:|------------:|
## |Letter_of_Alexander | 870| 15| 0|
## |Saint_Chad | 870| 6| 0|
## |Saint_Christopher | 870| 1| 0|
## |Martyrology | 875| 19| 0|
## |Anglo-Saxon Chronicle1 | 880| 4| 0|
## |Cura_Pastoralis | 891| 519| 1|
## |Bede | 895| 286| 0|
## |Boethius | 897| 140| 0|
## |Orosius | 898| 65| 0|
## |Augustine_Soliloquy | 899| 66| 0|
## |Charters1 | 900| 14| 0|
## |Leechbook(early) | 910| 92| 0|
## |Herbarium | 940| 14| 0|
## |Quadrupedibus | 940| 27| 0|
## |Nicodemus | 945| 3| 0|
## |Blickling_Homilies | 950| 80| 0|
## |Vercelli_Homilies | 950| 102| 0|
## |Benedictine_Rule | 965| 74| 0|
## |Charters2 | 980| 19| 0|
## |Chrodegang | 985| 93| 0|
## |Mary_of_Egypt | 989| 39| 0|
## |Saint_Euphrosyne | 989| 1| 0|
## |Seven_Sleepers | 989| 4| 0|
## |West-Saxon_Gospels | 990| 128| 1|
## |Aelfric_Catholic | 991| 157| 0|
## | _Homilies_I | | | |
## |Aelfric_Homilies | 991| 109| 1|
## | _Supplemental | | | |
## |Aelfric_Catholic | 994| 178| 1|
## | _Homilies_II | | | |
## |Distichs_of_Cato | 995| 4| 0|
## |Aelfric_Temporibus_Anni| 995| 4| 0|
## |Aelfric_Lives_of_Saints| 997| 173| 2|
## |Aelfric_Letters | 1000| 46| 3|
## |Aelfric_Old_Testament | 1005| 83| 0|
## |Anglo-Saxon Chronicle3 | 1007| 43| 0|
## |Wulfstan_Institutes | 1008| 9| 0|
## | _of_Polity | | | |
## |Leechbook(late) | 1010| 1| 0|
## |Wulfstan_Homilies | 1010| 34| 0|
## |Byrhtferth_Manual | 1011| 16| 0|
## |Wulfstan_Laws | 1014| 5| 0|
## | _of_Aethelred_VI | | | |
## |Lacnunga | 1020| 4| 0|
## |Apollonius | 1025| 7| 0|
## |Holy_Rood_Tree | 1030| 9| 2|
## |De_Ascensione | 1030| 2| 0|
## |James_the_Greater | 1030| 1| 2|
## |Saint_Eustace | 1030| 4| 0|
## |Saint_Margaret | 1030| 7| 0|
## | _(Tiberius) | | | |
## |Charters3 | 1050| 9| 0|
## |Saint_Margaret | 1060| 7| 0|
## | _(Corpus) | | | |
## |Saint_Neot | 1065| 4| 0|
## |Alcuin | 1070| 14| 3|
## | _Virtutibus_Vitiis | | | |
## |Anglo-Saxon Chronicle4 | 1101| 8| 0|
## |Eluciderium | 1108| 3| 3|
## |In_Festis_Sancti_Marie | 1110| 2| 1|
## |Anglo-Saxon Chronicle | 1131| 6| 4|
## | _Cont1 | | | |
## |Anglo-Saxon Chronicle | 1154| 0| 5|
## | _Cont2 | | | |
## |Lambeth_Homilies | 1160| 8| 27|
## | _(without_OE_copies)| | | |
## |Trinity_Homilies | 1165| 4| 161|
## | _(5_sermons_removed)| | | |
## |Vices_and_Virtues | 1180| 9| 125|
## |Ancrene_Riwle | 1215| 9| 242|
## |Hali_Meidhad | 1225| 5| 37|
## |Saint_Juliana | 1225| 0| 68|
## |Saint_Katherine | 1225| 5| 45|
## |Saint_Margaret | 1225| 3| 44|
## |Sawles_Warde | 1225| 4| 27|
Statistical analysis
Logistic regression
A manual inspection of the data in the table above shows that the Old English inflected infinitive disappeared quite rapidly during the 12th century. But a statistical model can put this intuition on a more objective footing. An appropriate model for the present data is logistic regression, which fits an s-shaped curve to the outcome of a binary, categorical dependent variable - here, whether the infinitive is inflected (coded as 1) or uninflected (coded as 0).
The logistic regression model was constructed in the free statistics software R. The R code that was used is explicitly shown below. A variable called inflinf (for 'inflected infinitive') stores the data. The dependent variable is called Realization_of_Infinitive, which consists of a two-column matrix with the number of inflected and uninflected examples for every text. The only independent variable in the model is called Year, which corresponds simply to the assumed date of composition for every text. The statistical model regresses Realization_of_Infinitive on Year in a generalized linear model with a binomial link function.
Realization_of_Inf = cbind(inflinf$Inflected_Examples,
inflinf$Uninflected_Examples)
Year = inflinf$Fitted_Year
logreg = glm(Realization_of_Inf ~ Year, family = "binomial",
data = inflinf)
summary(logreg)
##
## Call:
## glm(formula = Realization_of_Inf ~ Year, family = "binomial",
## data = inflinf)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -5.441 0.064 0.342 0.815 3.228
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 41.1193 1.6992 24.2 <2e-16 ***
## Year -0.0368 0.0015 -24.5 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 3354.14 on 62 degrees of freedom
## Residual deviance: 117.64 on 61 degrees of freedom
## AIC: 176.4
##
## Number of Fisher Scoring iterations: 6
The logistic regression model returns an intercept, 41.1193, and a coefficient for the independent variable Year, -0.0368. That means that for every one-year increase, the log-odds of finding an inflected infinitive as opposed to an uninflected one decrease by 0.0368. This factor is highly significant (for a chi-square test on the squared z-value). Hence, the date of a text does indeed make a huge difference for the realization of a to-infinitive as inflected or uninflected
The actual model from this logistic regression can be written down as follows. The log-odds of finding an inflected infinitive (as opposed to an uninflected infinitive) in a given year is predicted to correspond to the intercept plus the coefficient multiplied for that year.
Log-odds(Realization_of_Inf as inflected) = 41.1193 + (-0.0368) * Year
Here are three applications of this model to predict the probability of finding an inflected infinitive in the years 1000, 1100 and 1200.
# Prediction for 1000 A.D.
Log-odds(Realization_of_Inf as inflected) = 41.1193 + (-0.0368) * 1000
= 4.3193
= odds of 75.1 : 1
= a probability of 98.7%
# Prediction for 1100 A.D.
Log-odds(Realization_of_Inf as inflected) = 41.1193 + (-0.0368) * 1100
= 0.6393
= odds of 1.9 : 1
= a probability of 65.5%
# Prediction for 1200 A.D.
Log-odds(Realization_of_Inf as inflected) = 41.1193 + (-0.0368) * 1200
= -3.0407
= odds of 0.05 : 1
= a probability of 4.6%
So, in the year 1000, the probability of finding an uninflected to-infinitive is very small since better than 98% of all instances are expected to show up with an inflection. By 1100, a fair number of examples without an overt inflection should be found because the predicted probability of inflected infinitives has now decreased to just 65.5%. Finally, by 1200 the change is modelled as essentially complete since the logistic regression model predicts that fewer than 5% of all to-infinitives should occur with an inflectional ending.
Evidently, the logistic regression analysis provides a highly plausible model of what happened to Old English to-infinitives, given the data on the variation found in early English texts. Furthermore, the coefficient of the Year variable quantifies the rate of change. It provides a more objective slope for the more subjective assessment that the erosion of the infinitival inflection occured quite fast in the 12th century. Finally, the model can be tested empirically for example when it is used to predict the incidence of inflected to-infinitives in other early English texts that were not employed for the construction of the model.
Graphical representation
The following R code creates a graphical representation of the logistic regression model that shows the data points for each text as well as the s-shaped regression line.
library(ggplot2)
plot <- ggplot(data = inflinf, aes(x = Fitted_Year,
y = (Inflected_Examples/
(Inflected_Examples + Uninflected_Examples)),
size = log(Inflected_Examples + Uninflected_Examples),
group = 1)) +
xlab("Time") +
ylab("Proportion of Inflected Infinitives") +
scale_size_continuous(name = "Log Example Size",
limits = c(0, 6.5),
breaks = c(1, 2, 3, 4, 5, 6),
labels = c("1 (c. 3 examples)", "2 (c. 7 examples)",
"3 (c. 20 examples)", "4 (c. 55 examples)",
"5 (c. 150 examples)", "6 (c. 400 examples)")) +
geom_smooth(method = "glm", family = "quasibinomial",
formula = y ~ x, show_guide = FALSE) +
geom_point(colour = "#CC0000") +
theme(panel.grid.minor = element_blank(),
panel.grid.major = element_line(colour = "lightgrey",
size = 0.75))
plot
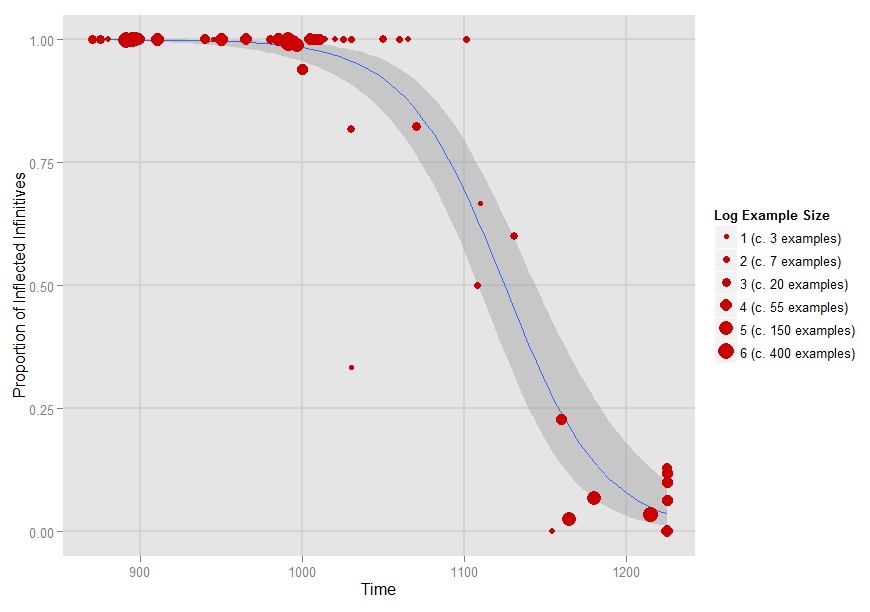
The size of a data point should be relative to the number of examples found in the text it represents. However, the number of examples varies substantially between different records. For instance, in the Old English Cura Pastoralis, there are more than 500 to-infinitives. In contrast, the Old English / Middle English transitional text Eluciderium contains only 6 examples of inflected and uninflected infinitives. Thus, some data points would be unreasonably large whereas others would be unrecognizably small. To overcome this problem, the graph scales the data points according to log example size (size=log(Inflected_Examples+Uninflected_Examples)). In this way, the smaller texts, especially those from the crucial late 11th and 12th centuries, remain visible while larger texts are still represented by larger data points.
The graph also includes a 95% confidence interval around the regression line (geom_smooth(…)). They are meant to convey the uncertainty inherent in results derived from empirical data and how reliable the estimated model parameters really are. The 95% confidence interval can be interpreted like this: Given the data sample that the confidence interval was calculated with, there is a probability of less than 5% that the the true Year parameter falling outside of this interval would occur by random chance. Or put differently, given the data sample that the confidence interval was calculated with, the difference between the estimated regression line based on observations and the true Year parameter being encompassed anywhere within the confidence interval would not be statistically significant at the 5% level.
- Go back to the Old-Engli.sh trivia article on inflected infinitives
- Find out more about statistics in R with the R cookbook
- Complaints, Comments, Commendations? Contact www.Old-Engli.sh here!